In the world of voice AI, the difference between a helpful assistant and a vague interaction is measured in milliseconds. Although text-based Retrieval-Augmented Generation (RAG) systems can provide a few seconds of ‘thinking’ time, voice agents must respond within 200 seconds.Mrs standard to maintain natural communication. Typical vector database queries typically add 50-300Mrs of network latency, which consumes the entire budget before the LLM starts generating a response.
The Salesforce AI research team has released VoiceAgentRAGopen source two-agent frameworks designed to avoid this retrieval problem by combining document retrieval into response generation.
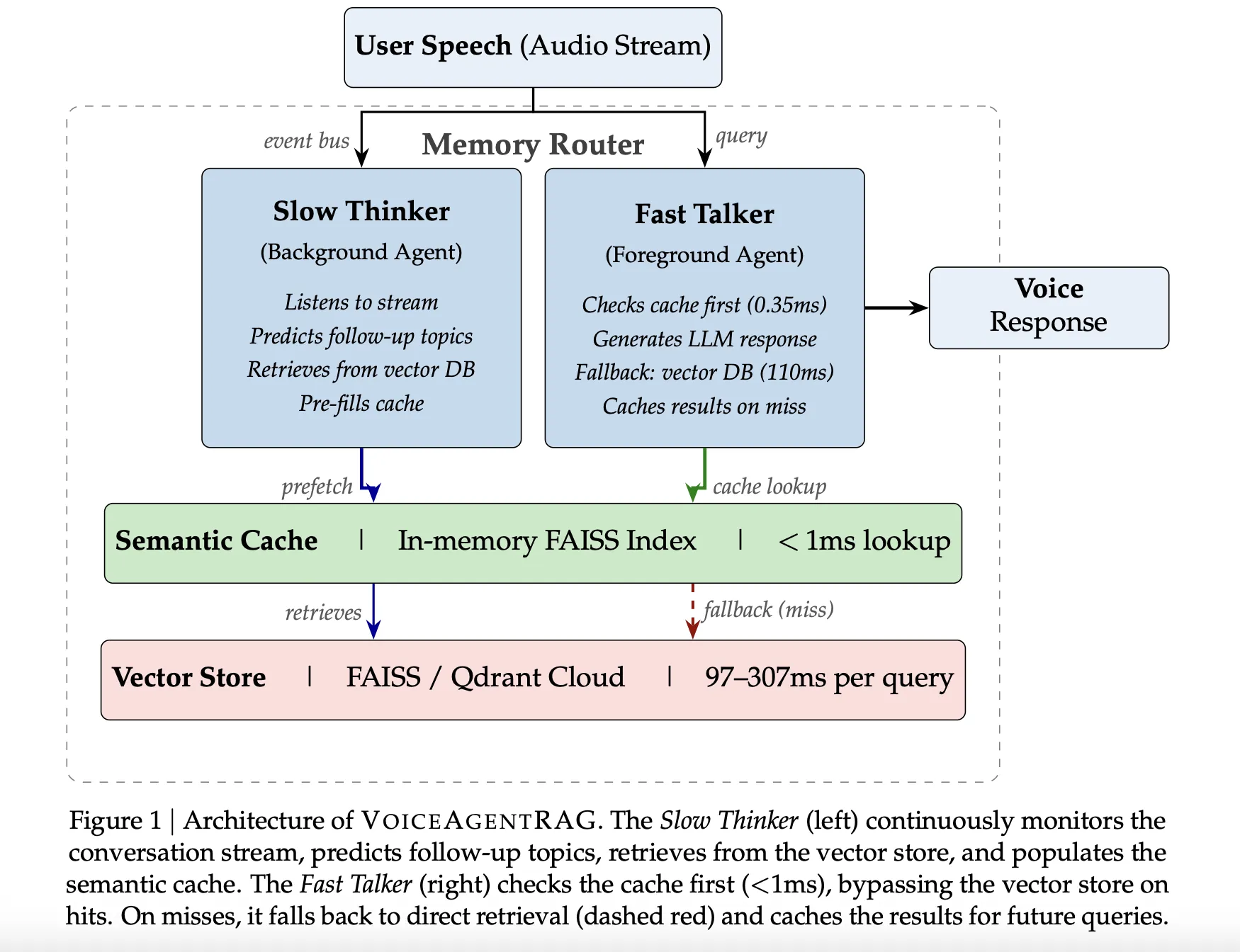
Dual Agent Design: Fast Talker vs. Slow Thinker
VoiceAgentRAG acts as a memory router that configures two parallel agents on a random event bus:
- The Fast Talker (front agent): This proxy handles critical path latency. For each user query, it starts by checking your memory space Semantic cache. If the required mean is present, the search takes about 0.35Mrs. When the cache misses, it returns to the remote vector cache and immediately stores the results for future changes.
- The Slow Thinker (Background Agent): Acting as a background task, this agent constantly monitors the communication stream. It uses a sliding window of the previous six conversations change to predict About 3–5 topics will follow. It then fetches relevant document fragments from the remote vector store into the local cache before the user utters their next query.
To improve search accuracy, Slow Thinker is ordered to display document type definitions instead of questions. This ensures that the resulting embeddings are more consistent with the actual prose found in the knowledge base.
Backend technology: Semantic Caching
The efficiency of the system depends on the specific semantic cache implemented in memory FAISS IndexFlat IP (internal product).
- Indexing-Embedding Indexing: Unlike passive caches that index by query context, VoiceAgentRAG indexes automatically filing documents. This allows the cache to perform an accurate semantic search on its contents, ensuring relevance even if the user’s phrase differs from the system’s predictions.
- Growth Management: Because query-to-document cosine similarity is systematically lower than query-to-query similarity, the system uses a default threshold of balancing accuracy and recall.
- Maintenance: Cache detects adjacent copies using a 0.95 cosine similarity threshold and he works a Soon Soon (LRU) eviction policy and a 300 seconds Time-To-Live (TTL).
- Important Returns: By deleting the Fast Talker database, a
PriorityRetrievalthe event causes the Slow Thinker to make an immediate search by extended top-k (2x default) quickly filling the cache around the new topic area.
Standards and Performance
The research team tested the operating system Qdrant cloud such as distance vector storage to 200 questions and 10 discussion levels.
| Metric | Performance |
| Total Cache Hit Rate | 75% (79% in warm seasons) |
| To restore Speedup | 316x |
| Total Recovery Time Saved | 16.5 seconds over 200 turns |
Architecture works best in the context of cohesive or sustainable content. For example, ‘Comparison of parts’ (S8) achieved a 95% hit rate. On the other hand, the process is embedded in uncertain conditions; the lowest level was ‘Customer development available’ (S9) to a 45% hit ratewhile ‘Mixed quick-fire’ (S10) saved 55%.
Integration and Support
The VoiceAgentRAG repository is designed for extensive interoperability across the AI stack:
- LLM Scholarships: Support OpenAI, Anthropic, Gemini/Vertex AIand Being. An example of a regular exam paper was GPT-4o-mini.
- Included: Research is used OpenAI text-embedding-3-small (1536 measurements), but the archive provides support for both OpenAI and Being included.
- STT/TTS: Support Whisper (local or OpenAI) for speech-to-text and TTS status or OpenAI for text-to-speech.
- Vector Shops: Built-in support for PLEASURE and Quadrant.
Important information
- Two Pronoun Constructions: The system solves the RAG latency bottleneck by using a front-end ‘Fast Talker’ for sub-millisecond caches and a back-end ‘Slow Thinker’ for prefetching.
- Important Speedup: Achieves 316x recovery speed to cache hits, which is important for staying within the natural 200ms voice response time limit.
- High Cache Performance: Across different scenarios, the system maintains an overall cache hit rate of 75%, peaking at 95% for coherent conversations such as feature comparisons.
- Document-Indexed Caching: To ensure correctness regardless of the user’s words, the semantic cache indexes are included in the papers instead of the pre-defined query entry.
- The First Look: The back-end agent uses a sliding window of the last 6 conversations to guess which topics are likely to be followed and fills the cache during natural pauses.
Check it out Paper and Repo here. Also, feel free to follow us Twitter and don’t forget to contact us 120k+ ML SubReddit and Subscribe to Our newsletter. Wait! are you on telegram? now you can contact us on telegram again.
#Salesforce #Research #Releases #VoiceAgentRAG #twoperson #InMemory #Router #reduces #Voice #RAG #retrieval #time #316x